
Primary Key (PK) identifies uniquely each row in a table. There can never be two tuples with same values in PK.
There are two ways of defining a PK: a natural key or a surrogate key. I would say that if you can find a natural key that is always better. But it is not always possible and therefore we can also use surrogate PKs. Surrogates are usually sequence numbers that has no meaning to the business people, the end users.
Let’s have an example of an entity for all the users in a company.


1. Defining a natural PK
What I want is that there will never be more than one user with the same username. If this means that there can NEVER be two with the same username, I would define the PK like this:

You can see the PK definition from Unique Identifiers tab:

And by clicking the Properties button (XYZ and a pen) you can see and edit the properties for this unique identifier.
You can for instance change the name
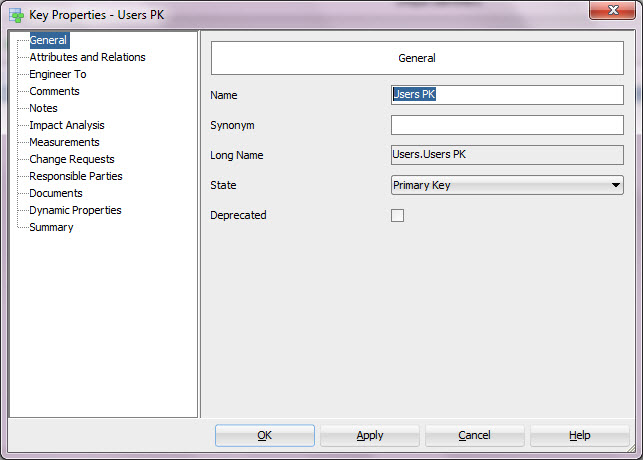
Or see what attributes or relationships are involved in this PK. You can add or remove attributes or relationships to/from the PK using the arrows pointing to right and left. And you can change the order of the PK elements using the arrows pointing up and down.

If the requirement would be that there can never be two users at the same time with a same valid username I might think a bit. If I am sure that a pair (Username, Valid) would be enough as a PK, it means that I can only have max two users with the same Username: one with Valid=true and another one with Valid=false, I could define that as the PK, but what happens when the second one needs to be disabled eg. Valid changed to false? Then I would have two tuples with same values in Username and Valid, that would not work because that is my PK. So having a PK with just Username and Valid would not be quite smart. I could also use Created date in PK but would that be smart? No. Having a PK (Username, Valid, Created) would help me to disable a username even though there is already another of the same Username disabled or adding the third user with the same Username but it would not guarantee that only one user would have that Username at a point of time. And that was exactly what the requirement was.
I could add BeginDate and EndDate as attributes:

But that would not help me because I could not use those attributes in the PK because I should be checking that the two rows are not valid at the same time, eg. comparing the BeginDates and EndDates for all rows having the same Username. Of cause I could check those attributes using PL/SQL and check that only one row is valid at a time but that is not a PK.
No wonder many people end up to the conclusion that the requirement means that there can NEVER be two users with the same Username 🙂 Then the PK (Username) would be sufficient.
But what if the requirement really is that there cannot be more than one at the same point of time? Then I would use surrogate as the PK and use PL/SQL (trigger) for checking the rest.
2. Defining a surrogate PK
There are two ways to define a surrogate PK: manually or automatically.
If I want to create it manually, I simply define an attribute for it and define it as the PK. My recommendation is that if this is the way you want to work, start by defining a Domain for surrogates and always use that when defining a surrogate PK manually. Otherwise defining a surrogate PK manually is done just like I explained earlier on Defining a natural PK.
You can also define a surrogate PK automatically. In entity properties enable Create Surrogate Key and when you engineer to relational model, this surrogate key and the surrogate column are created automatically.

If using surrogate keys is the preferred way of working for you, you might consider enabling that property so that the default would be Create Surrogate Key enabled.

Remember that you can define the naming standard for the surrogate key and the column created in Design Properties (right-click on the Design name and select Properties):

This was a quick look to PKs. A natural key is always the best and being able to define one you must know the requirements and understand them. If a natural key does not work, then a surrogate key is an option.

Pingback: What’s In A (User) Name? | Oracle Tips and Tricks -- David Fitzjarrell
Pingback: What’s In A (User) Name? - Oracle - Oracle - Toad World
Reblogged this on The Data Warrior and commented:
A good “how to” article from Heli for those just getting started with Oracle Data Modeler. Don’t forget you get more good information like this from her new Oracle Press book on Amazon.com: Oracle SQL Developer Data Modeler.
Model on!
Kent
The Data Warrior
Pingback: Write Less with More - Part 2 (Identity Columns) - DB OrientedDB Oriented
Pingback: » Some Oracle Bloggers You Should Check Out
Heli,
Here’s a solution for your primary key constraint on usernames, Add a computed column to your table that returns an impossible date such as to_date(‘1′,’j’) when the username is valid and otherwise returns the created date. Then add the computed column to your primary key constraint:
ALTER TABLE USERS ADD (COMPUTED DATE AS ( decode(valid,1,to_date(‘1′,’j’),created) ) VIRTUAL NOT NULL);
ALTER TABLE USERS DROP CONSTRAINT USERS_PK;
ALTER TABLE USERS ADD CONSTRAINT USERS_PK PRIMARY KEY
(
USERNAME
, VALID
, COMPUTED
)
ENABLE;
If you’d rather not use a magic value in the virtual column, you can stick with a surrogate key as primary, but define the virtual column as decode(valid,1,null,created) allowing nulls and define a unique constraint the similarly to the primary key above. The unique constraint will then enforce the uniqueness requirement on active usernames but allow for multiple inactive usernames.
Thank you. I am sure there are many technical solutions for this but my original idea was to explain the process of selecting the right PK to meet the requirement and how to design that using Data Modeler. I did get a bit carried away with that and went to more details, though 🙂 Thank you for your comment!